プレスリリース
集団が急激な環境変化に柔軟に対応できるための 認知・行動メカニズムを理論的に解明
■発表のポイント
◇情報技術やAIの急速な進展と共に、現代社会の情報環境は日々激しく変化する。数ヶ月前に最適だった選択が、今日の環境ではもはや「時代遅れの不適切な選択」であることも多い。
◇こうした「急激に変化する不確実な環境」において、人々が互いの行動を参照しあうプロセスが、社会的な決定を改善あるいは劣化させる条件を理論的に検討した。
◇私たちが他者の行動を参照するときの仕組み(「社会学習のアルゴリズム」)に着目し、質的に異なる2つの学習タイプが集団に共存することで、効率的かつ柔軟な意思決定が実現できることを示した。
◇本研究の知見は、人間とAIが共在する現代の情報空間において、多様性を活かした優れた社会的意思決定をデザインする原理について重要な示唆を与える。
■発表概要
東京大学大学院人文社会系研究科社会文化研究専攻の菅沼秀蔵 大学院生、産業技術総合研究所・人間情報インタラクション研究部門の片平健太郎研究グループ長、総合研究大学院大学・統合進化科学研究センターの大槻久教授、明治学院大学情報数理学部・情報科学融合領域センターの亀田達也教授(責任著者)らの研究グループは、急激に変化する情報環境において、人々が互いを参照する「社会学習」を通じ、同時達成の難しい「意思決定の効率性(良い選択肢への素早く効率的な集中)と柔軟性(選択肢の時間的変化への対応)」という2つの目標を両立・実現するメカニズムを理論的に明らかにしました。認知神経科学では、人々が互いを参照しあう社会学習のメカニズムとして、(1)価値形成(value shaping; VS)、(2)決定バイアス(decision biasing; DB)、と呼ばれる2つの対照的な仕組み(「アルゴリズム」)が提案されています。価値形成(VS)型の社会学習では、人は多くの人々が選択した「人気の選択肢」を、本当に価値の高い選択肢として評価します。たとえば、人気のレストランの料理をそのまま美味しいと感じるといった評価のしかたです。これに対して、決定バイアス(DB)型の社会学習では、「人気の選択肢」を選びやすくなる一方で、選択肢の価値は人気ではなく自分の実際の経験だけに基づいて評価します。たとえば、人気のレストランに自分も出かける一方、料理の味そのものは「自分の味覚」だけで独立に判断するという評価のしかたです。本研究では、VS型の社会学習を行う人々からなる集団は、安定した環境では優れた選択に迅速に収束できる反面、急速な変動が起きる環境では時代遅れの選択にいつまでも囚われてしまうことが明らかになりました。一方、DB型の社会学習を行う人々からなる集団は、安定した環境での効率性は下がるものの、急激な変動に対しても柔軟に対処できる(過去に囚われない)という特性を持ちます。本研究の重要なポイントは、これらの2つのタイプは集団の中で安定して共存でき(「進化的安定性」)、それぞれが互いの短所を補いあうことで、急速に変動する環境においても、集団全体としてより高いパフォーマンスを達成しうることを示した点です。本研究の知見は、人間とAIが共在しつつある現在・近未来の情報空間で、優れた集団での意思決定をデザインするための原理について重要な示唆を与えます。
本研究成果は、2025年11月24日に米国科学アカデミー紀要(Proceedings of the National Academy of Sciences of the United States of America)にて公開されました。
■発表内容
自分以外の他の個体から学習する「社会学習」は、ヒトを含む幅広い動物種で見られる現象です。SNS上の投稿や商品のレビュー、先生や年長者からの教育的な指導、専門家の見解などのさまざまな社会的情報は、優れた意思決定を下すための重要な情報源です。また、アリやミツバチなどの社会性昆虫も、フェロモンの分泌や「8の字ダンス」などのメカニズムを通じて個体間で互いに影響を与え合いながら、効率的な採餌を行うことが知られています。このように、社会学習は集団としてより良い意思決定を行うための重要な要因ですが、社会的影響はときに環境の変化に対する人々の柔軟性を損ない、劇的なまでの「集合愚」をもたらす可能性があります。本研究では、動的に変化する環境において相互作用する集団が意思決定の効率性(優れた選択肢への素早い収束)と柔軟性(選択肢の時間的変化への対応)を両立できる条件を理論的に明らかにしました。
これまでの認知神経科学の研究では、強化学習(注1)の枠組みに基づいて人の社会学習の仕組みを数理的にモデル化することが試みられてきました。近年では特に価値形成(value shaping; VS)型と決定バイアス(decision biasing; DB)型という2つの計算アルゴリズムの類型が注目を集めています(図1)。VS型のアルゴリズムでは、他者の行動は選択肢の価値を評価するための「擬似的な報酬」として利用されます。これに対し、DB型のアルゴリズムでは、他者と同じ選択を取りやすくなる一方、選択肢の評価は自己の経験のみに基づくのが特徴です。これら2つのアルゴリズムはいずれも適応的な意思決定を実現すると考えられますが、相互作用する集団において両者がどのように機能するのかは、これまで明らかにされていませんでした。また、実験研究ではヒトの社会学習が概してVS型のアルゴリズムで説明されることが示されてきましたが、同時に個人差の存在も示唆されており、その由来に対する理論的な説明はなされていませんでした。
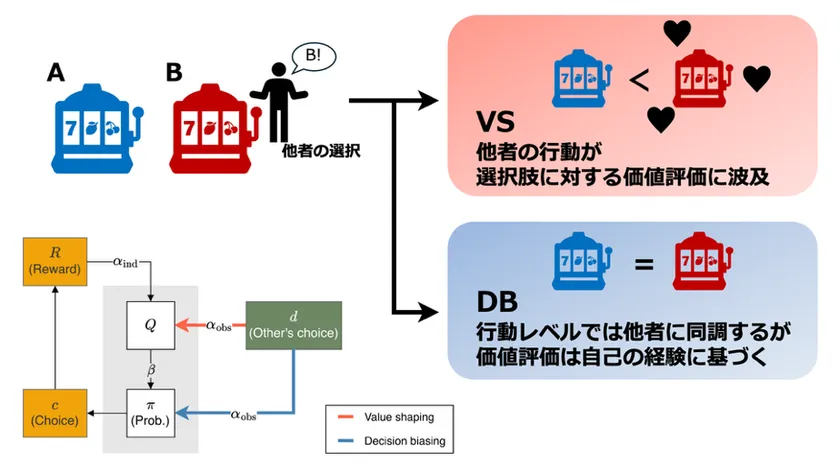
図1 2つの社会学習アルゴリズムの違い
図1 2つの社会学習アルゴリズムの違い。価値形成(VS)型のアルゴリズムでは他者の行動が選択肢に対する価値評価に直接的に波及するのに対して、決定バイアス(DB)型では価値評価はあくまでも自己の報酬経験に基づきます。
本研究では、多数派同調(集団内の多数派から優先的に学習するバイアス)、情報共有のメカニズム(全個体の選択がすべて共有される状況か、正の報酬を獲得した個体の選択のみ共有される状況)、および集団サイズ(ペア~100人集団)を体系的に操作し、2つの社会学習アルゴリズムに従うエージェント(行為者)からなる集団の意思決定パフォーマンスを調べました。エージェントベースシミュレーション(注2)を実施した結果、VS集団は安定した環境において優れた選択肢に迅速に収束する一方、急速な環境変動に対してはDB集団がより柔軟に対応できるというトレードオフの関係が明らかになりました。特に、多数派による社会的影響が強い状況において、VS集団は環境の変化にうまく対応できないことが示されました(図2)。この結果は、急激に変化する現代のネット空間に特徴的な大規模な相互作用場面において、ほとんどの人々がデフォルトで採用しているVS型の社会学習の仕方が脆弱である可能性を浮き彫りにしています。
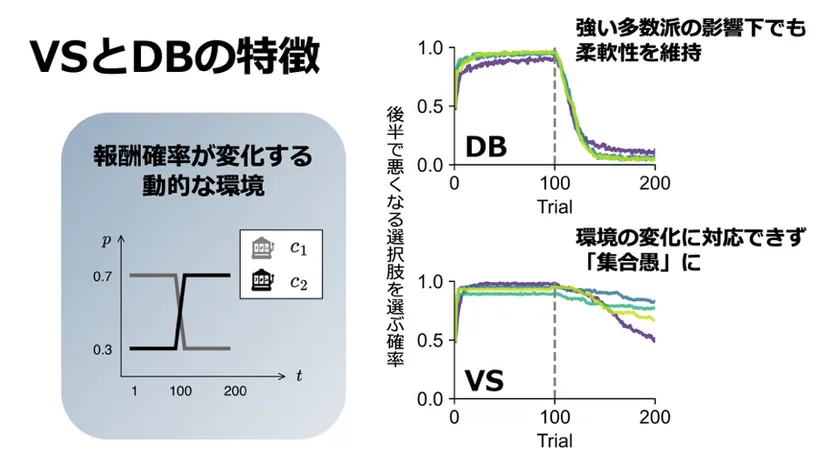
図2社会学習アルゴリズムが生み出す集団レベルの帰結
図2 社会学習アルゴリズムが生み出す集団レベルの帰結。このシミュレーションでは報酬確率が異なる2つの選択肢があり、それらの報酬確率が途中で逆転する、という状況を想定しました(図の左のように、選択肢C1では報酬の出る確率が途中で0.7から0.3に低下し、選択肢C2の報酬確率と反転します)。図の右に示すように、DB型は前半でC1を選び後半ではそれを選ばなくなる(=C2を選ぶようになる)一方、VS型では後半でもC1を選び続けています。このように、DB型のアルゴリズムに従うエージェントは多数派からの影響が強く受ける条件でも環境の変化に柔軟に対応することができましたが、VS型は「時代遅れの選択肢」に固着してしまい、パフォーマンスを大きく下げることがわかりました。
さらに、2つの学習アルゴリズムが集団内に併存する状況で進化ダイナミクス(注3)を可視化したところ、両者が集団内で安定的に共存しうる状態が広い範囲で実現することが明らかになりました。加えて、単独では環境変動に対して脆弱なVS型のエージェントがより柔軟なDB型と組み合わされることによって、集団全体として意思決定パフォーマンスをいっそう改善することが示されました。この結果は、意思決定の効率性と柔軟性をうまく両立するうえで、集団内の多様性が重要な役割を果たすことを示唆しています(図3)。
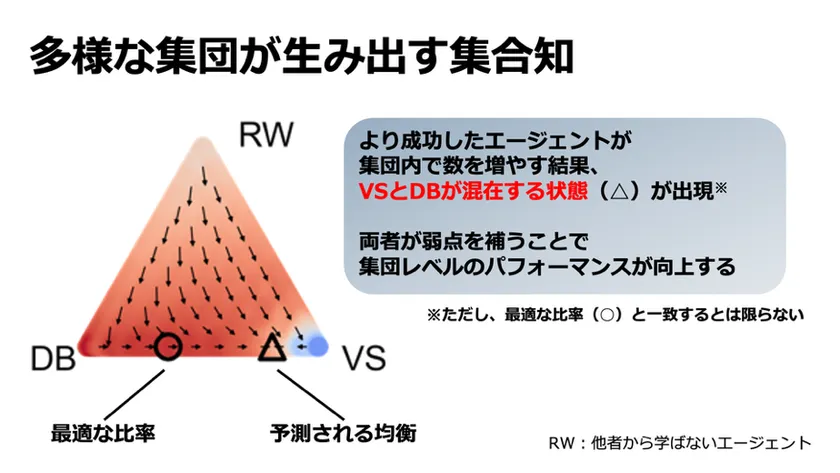
図3進化ダイナミクスの可視化
図3 進化ダイナミクスの可視化。ここではDB型とVS型および他者から学ばないRW型の3つのタイプが混在している集団の意思決定パフォーマンスを調べました。三角形上の各点は集団の構成比に対応しており、矢印は相対的にパフォーマンスが高かったタイプが集団内で数を増やしていった場合に構成比がどう変化するのかを示しています。その結果として、DB型とVS型が共存する状態が出現することが示されました。両者が適切な比率で混在している場合に、互いの弱点を補うことによって集団レベルで高いパフォーマンスが実現しうることがわかります。
本研究の知見は、個体レベルのアルゴリズムの違いが集団レベルで異なる帰結を生み出すメカニズムや、個々の多様性が集団内に維持される理由を理論的に明らかにしたものです。また、個体レベルの計算のプロセスが集団レベルの動態を規定するという発想は、人間とAIが共在する情報空間においてより良い集合的意思決定をどのようにデザインできるのかという喫緊の工学的問題に対して応用可能です。本研究で示した理学的知見は、災害やパンデミックなどの不確実な状況で見られる同調圧力の過剰な高まりや誤情報の拡散、陰謀論信念の普及といった問題に対する社会工学的なアプローチを考えるための重要な基礎づけになると考えられます。
■発表者・研究者等情報
東京大学 大学院人文社会系研究科社会文化研究専攻
・菅沼秀蔵 大学院生
産業技術総合研究所 人間情報インタラクション研究部門
・片平健太郎 研究グループ長
総合研究大学院大学 統合進化科学研究センター
・大槻久 教授
明治学院大学 情報科学融合領域センター
・亀田達也 センター長
(兼:明治学院大学情報数理学部 教授)
■論文情報
雑誌名: Proceedings of the National Academy of Sciences of the
United States of America
題名 : How social learning enhances-or undermines-efficiency and
flexibility in collective decision-making under uncertainty
著者名: Hidezo Suganuma, Kentaro Katahira, Hisashi Ohtsuki, and
Tatsuya Kameda* (*責任著者)
DOI : 10.1073/pnas.2516827122
URL : https://www.pnas.org/doi/10.1073/pnas.2516827122
■研究助成
本研究は「JST次世代研究者挑戦的研究プログラム(課題番号:JPMJSP2108)」、「科研費基盤研究(A)(課題番号:JP23H00074)」、「科研費基盤研究(C)(課題番号:JP24K15121)」の支援により実施されました。
■用語解説
(注1)強化学習(reinforcement learning)
エージェントが環境から与えられる報酬を最大化することを通じて適切な行動を学習する機械学習の手法。心理学・行動科学の領域においてヒトやその他の動物の知性を理解するための基礎理論となっているほか、近年ではロボットの制御や言語モデルをはじめとする人工知能(AI)の開発にも幅広く応用されています。
(注2)エージェントベースシミュレーション(agent-based simulation)
個々の主体(エージェント)がシンプルな学習・行動規則に従って動く様子をコンピュータ上で再現することにより、集団全体の振る舞いを調べる研究手法のこと。
(注3)進化ダイナミクス(evolutionary dynamics)
ここでは、集団内で相対的にパフォーマンスが高かった戦略(社会学習アルゴリズムのタイプ)が、その数を増やしていくプロセスのこと。